Analysis of 2D data (MATLAB)¶
This MATLAB notebook demonstrates how 2D data can be analyzed using spm1d.
Note: Currently spm1d can be used only for non-parametric analysis of 2D data.
Warning: 2D data must be registered prior to analysis. spm1d does not support 2D registration. Algorithmic registration of 2D data can be achieved with third-party software like ITK. Manual registration of 2D data is possible with software like 3D Slicer.
Warning: Probability values can not be calculated. Hypothesis testing is possible (i.e., critical test statistic calculation), but spm1d does not support cluster-specific probability calculations for 2D data.
Dataset¶
The 2D data analyzed below are from Pataky (2012), and include 20 pressure plate measurements of quiet standing in a single subject. Ten measurements were made for each of two quiet standing tasks: backward leaning and forward leaning. For the first ten measurements the subject leaned backward while maintaining toe contact, and for the next ten measurements the subject leaned forward while maintaining heel contact. Pressure distributions were recorded at 50 Hz for 5 s with a spatial resolution of 8.5 mm.
The attached dataset represents the average 2D pressure distribution (units: kPa) over the 5 s recorded interval. Each of the 20 observations is saved as a (60 x 32) array of pressure values. While the subject was required to step off the measurement plate between each measurement, thus implying non-constant foot positions with respect to the measurement device’s coordinate system, the attached data have been pre-registered following Oliveira et al. (2010).
The goal of the analyses below is to test the null hypothes of equal pressure distributions in the two tasks.
References¶
Oliveira FP, Pataky TC, Tavares JM (2010). Registration of pedobarographic image data in the frequency domain. Computer Methods in Biomechanics and Biomedical Engineering 13(6): 731-40.
Pataky TC (2012). Spatial resolution in plantar pressure measurement revisited. Journal of Biomechanics 45(12): 2116-24.
Importing and visualizing the data¶
The data are saved the “data2d” file and can be imported as follows:
[1]:
load('data2d.mat', 'Y')
disp( size(Y) )
20 60 32
Note that the data are saved in a single 3D array with dimensions (20, 60, 32), implying 20 measurements of (60 x 32) pressure distributions. Individual observations can be visualized like this:
[2]:
I = squeeze( Y(1,:,:) );
I(I<eps) = nan;
h = pcolor(I);
set(h, 'edgecolor', 'none');
colormap( jet )
axis image
cbh = colorbar;
cbh.Label.String = 'Average pressure (kPa)';
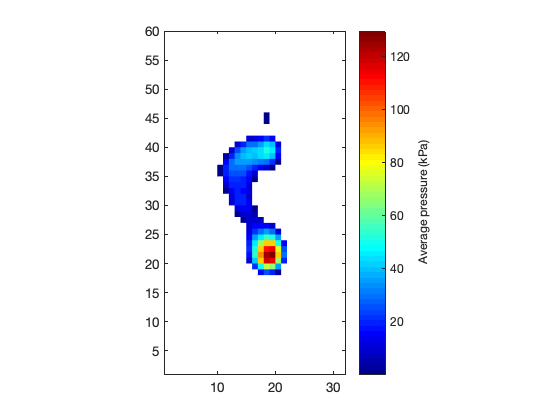
This represents a single observation of backward leaning. All observations can be visualized as follows.
[3]:
row1 = [];
row2 = [];
for i = 1:10
row1 = [row1 squeeze(Y(i,:,:))]; %#ok<AGROW>
row2 = [row2 squeeze(Y(10+i,:,:))]; %#ok<AGROW>
end
I = [row1; row2];
I(I<eps) = nan;
h = pcolor(I);
colormap( jet )
set(h, 'edgecolor', 'none');
axis image
cbh = colorbar;
cbh.Label.String = 'Average pressure (kPa)';
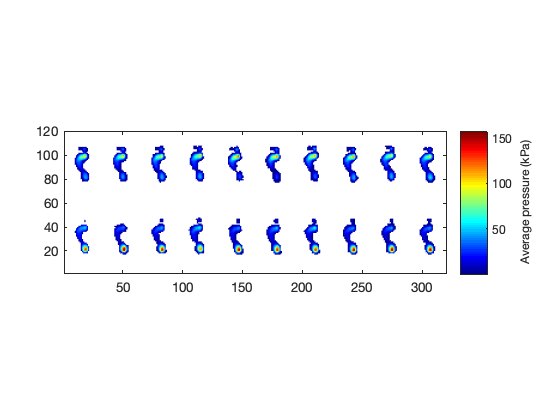
The backward and forward leaning trials are depicted in the top and bottom rows, respectively.
The mean distributions for the two tasks can be computed and visualized as follows:
[4]:
mA = squeeze( mean( Y( 1:10,:,:) , 1 ) );
mB = squeeze( mean( Y(11:20,:,:) , 1 ) );
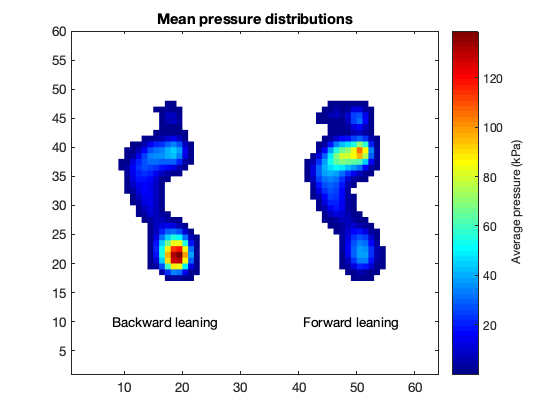
m = [mA mB];
m(m<eps) = nan;
h = pcolor(m);
colormap( jet )
set(h, 'edgecolor', 'none');
axis image
cbh = colorbar;
cbh.Label.String = 'Average pressure (kPa)';
title('Mean pressure distributions')
text(17, 10, 'Backward leaning', 'horizontalalignment', 'center')
text(49, 10, 'Forward leaning', 'horizontalalignment', 'center')
Statistical analysis¶
A two-sample t test can be conducted on these data using spm1d as follows.
The data must be flattened so that each observation is a 1D array.
[5]:
[J,q0,q1] = size(Y);
Q = q0 * q1;
y = zeros(J, Q);
for i = 1:J
y(i,:) = reshape( Y(i,:,:), 1, [] );
end
disp([J Q])
20 1920
Here J is the number of observations and Q is the number of nodes in the flattened 1D array.
For some types of 2D data, including the pressure distributions above, some nodes can contain zeros for all observations, implying zero variance and thus that test statistic values cannot be computed for these nodes. To avoid this problem it is desireable to remove zero-variance nodes like this:
[6]:
%separate the observations:
yA = y( 1:10,:,:); %flattend observations for Task A
yB = y(10:20,:,:); %flattend observations for Task B
%find zero-variance nodes:
iA = std(yA, [], 1) > eps; %Task A indices where variance > 0
iB = std(yB, [], 1) > eps; %Task B indices where variance > 0
i = iA & iB; %indices where variance > 0 for both tasks
ynz = y(:,i); %all observations with non-zero variance nodes removed
ynzA = ynz( 1:10,:); %Task A observations with non-zero variance nodes removed
ynzB = ynz(11:20,:); %Task B observations with non-zero variance nodes removed
Here a two-sample t test will be used. Note that the same procedure can be used for any test in spm1d.stats.nonparam.
[7]:
snpm = spm1d.stats.nonparam.ttest2(ynzA, ynzB);
snpmi = snpm.inference(0.05, 'two_tailed', true, 'iterations', 10000);
That’s it!
Here alpha=0.05 is the Type I error rate, and iterations=10000 is the number of iterartions used to build the nonparametric distribution for the test statistic. The number of iterations should be as large as is necessary to achieve numerical stability in the critical threshold, which is indicated below. Here “numerical stability” implies that quantitative changes in the critical test statistic value do not produce qualitative changes in the statistical results. Quantitative changes in
the critical test statistic arise due changes in the number of iterations and/or in the randomization state.
As a rule-of-thumb, at least 1000 iterations are needed, with 10,000 preferred. Also as a rule-of-thumb, run an re-run analyses a number of times to ensure numerical stability.
The spm1d results need to be reverted to the original 2D state for visualization. This can be achieved as follows.
[8]:
znz = snpmi.z; %flattened test statistic (i.e., t value) over only non-zero-variance nodes
zstar = snpmi.zstar; %critical test statistic (i.e., critical t value)
z = zeros(1,Q); %flattened test statistic including all nodes
z(i) = znz; %add test statistic values for the non-zero-variance nodes
Z = reshape(z, [q0 q1]); %2D test statistic image
Zi = Z; %2D inference image (temporary)
Zi(abs(Z)<zstar) = 0; %thresholded test statistic image
ZZ = [Z Zi]; %both raw test statistic image and inference image
ZZ(abs(ZZ)<eps) = nan;
%plot:
h = pcolor(ZZ);
colormap( jet )
caxis([-15 15])
set(h, 'edgecolor', 'none');
axis image
cbh = colorbar;
cbh.Label.String = 't value';
title('SPM results')
text(16, 10, 'Raw SPM', 'horizontalalignment', 'center')
text(48, 10, 'Inference', 'horizontalalignment', 'center')
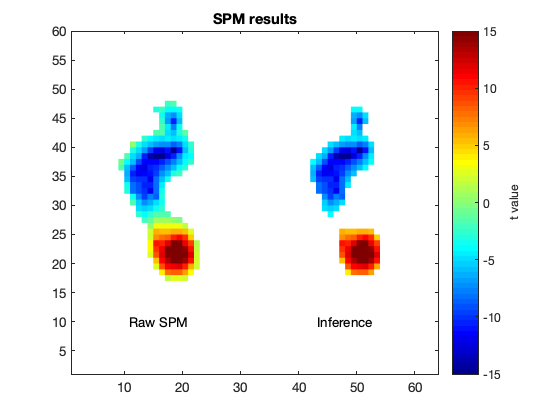
The “Raw SPM” image depicts the t values for all non-zero-variance nodes. The “Inference” image is the same, but is thresholded using the critical test statistic. In this case there are nodes whose t values exceed the critical t value, implying that the null hypothesis is rejected.
Summary¶
spm1d can be used to conduct nonparametric statistical inference on 2D data, but currently only supports hypothesis testing (i.e., critical test statistic calculation) and does not provide cluster-specific p values. Users requiring cluster-specific values can use another SPM packages like SPM12 or nipy.