Summary statistics¶
The examples below describe spm1d’s basic summary statistic functionality, which is housed in spm1d.plot.
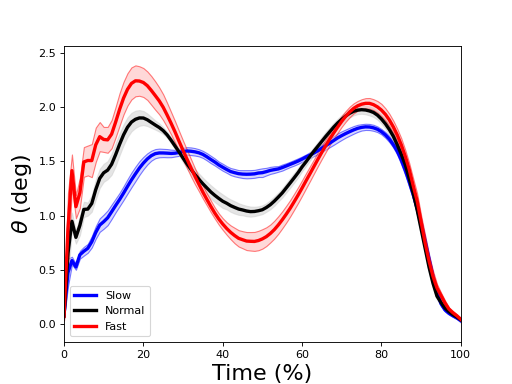
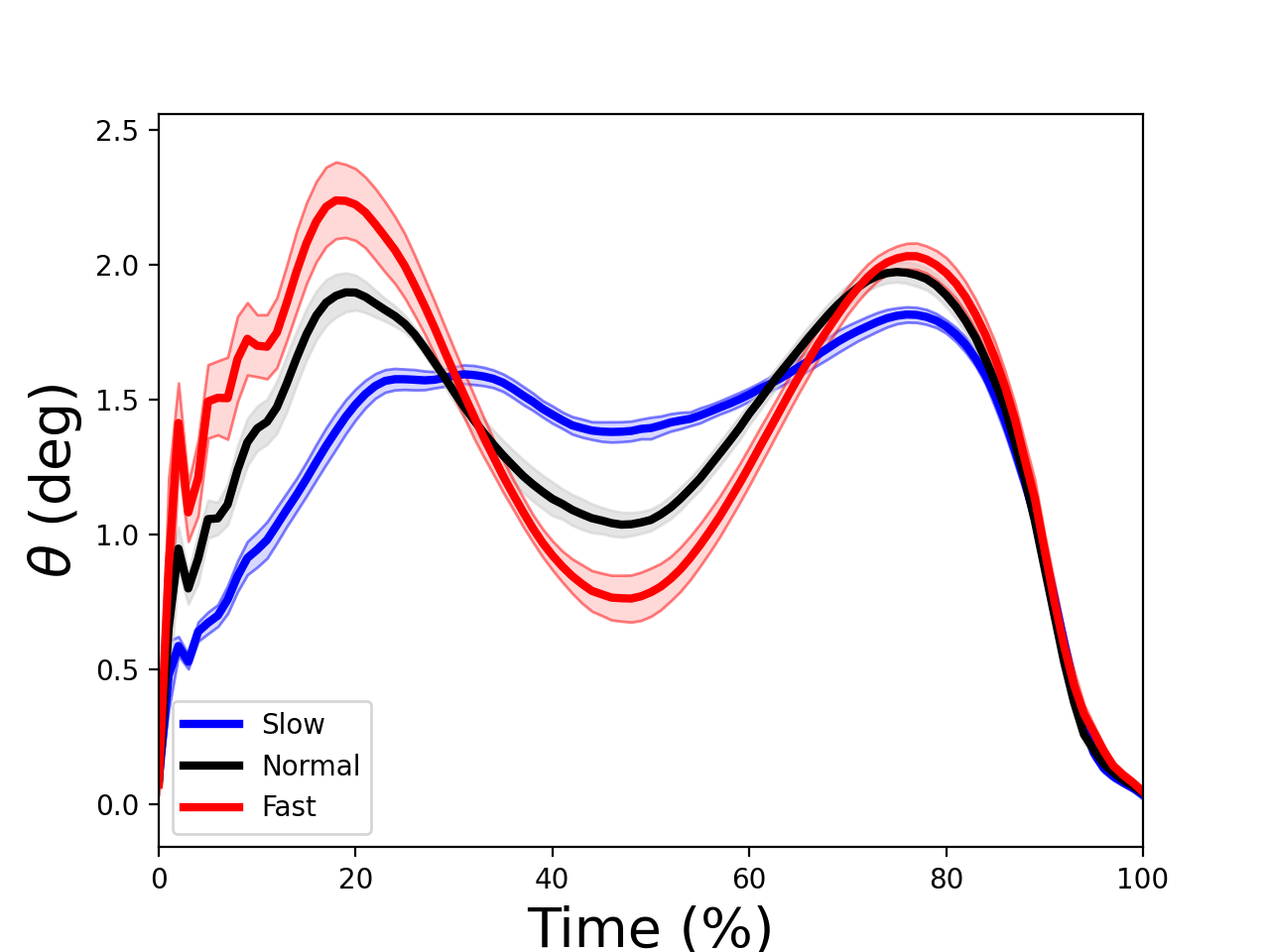
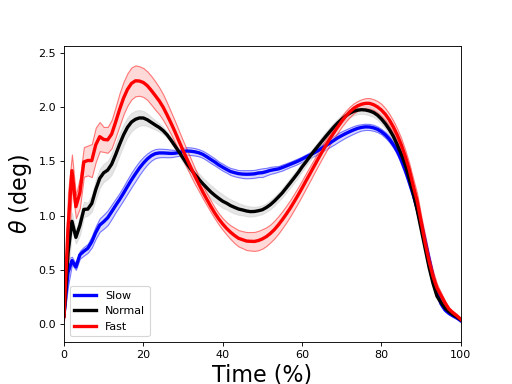
Means and SD clouds¶
./spm1d/examples/summarystats/ex_plot_meansd.py
Load data:
>>> dataset = spm1d.data.uv0d.anova.SpeedGRFcategorical()
>>> Y,A = dataset.get_data()
>>> Y1 = Y[A==1]
>>> Y2 = Y[A==2]
>>> Y3 = Y[A==3]
Each variable (Y1, Y2 and Y3) is a (20 x 100) data array. Mean and standard deviation clouds can be plotted as follows:
>>> spm1d.plot.plot_mean_sd(Y0, linecolor='b', facecolor=(0.7,0.7,1), edgecolor='b', label='Slow')
>>> spm1d.plot.plot_mean_sd(Y1, label='Normal')
>>> spm1d.plot.plot_mean_sd(Y2, linecolor='r', facecolor=(1,0.7,0.7), edgecolor='r', label='Fast')
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
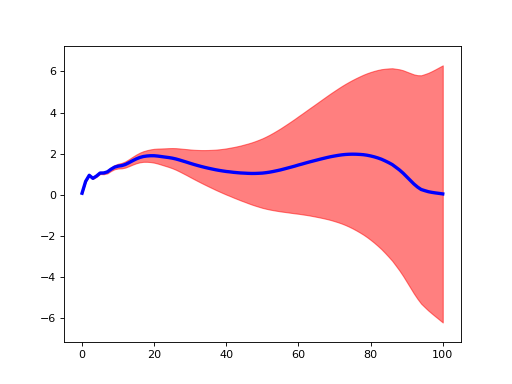
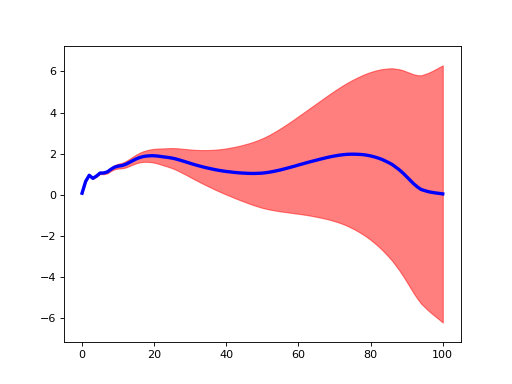
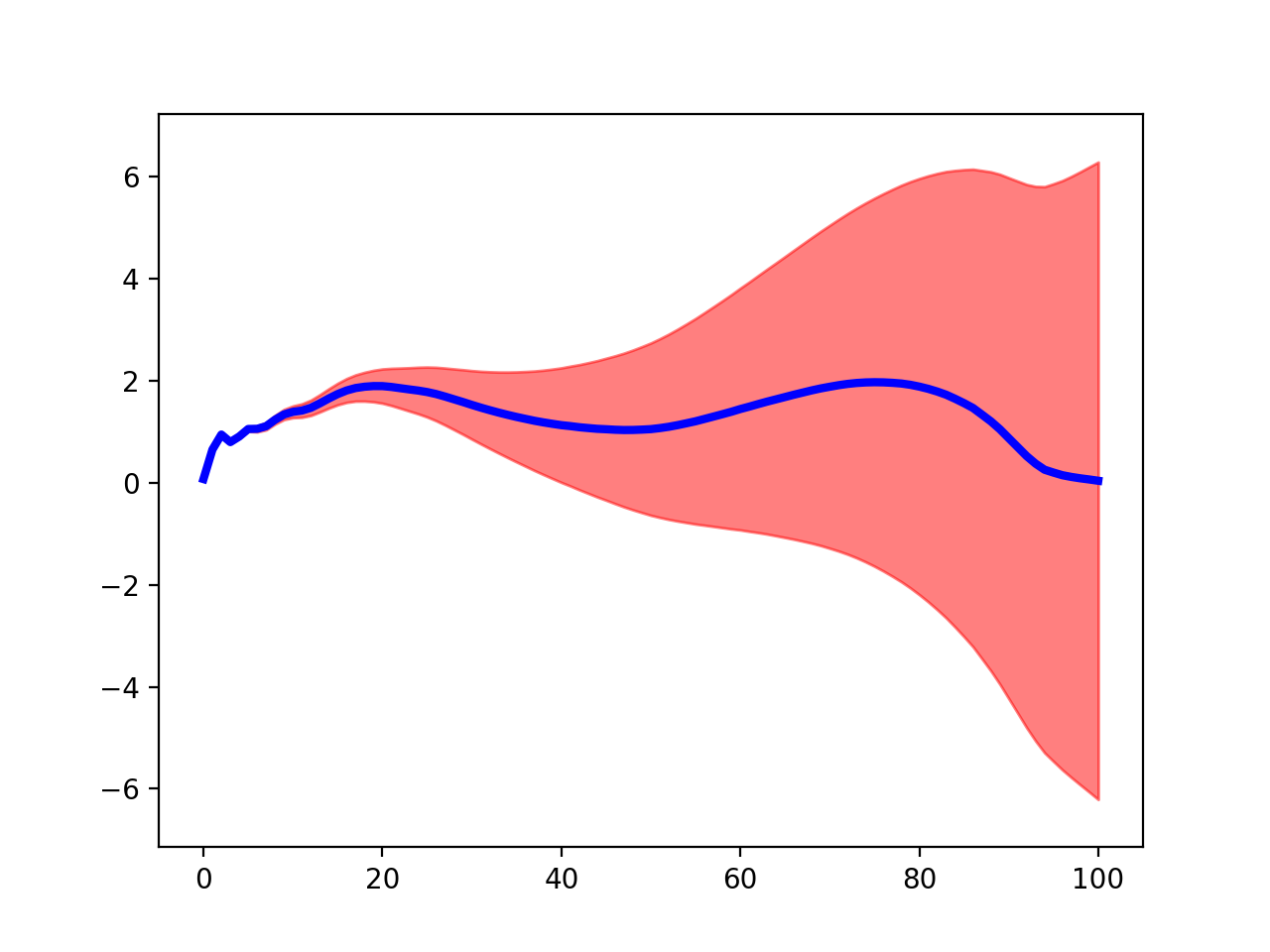
Arbitrary variance clouds¶
./spm1d/examples/summarystats/ex_plot_errorcloud.py
>>> Y0,Y1,Y2 = spm1d.util.get_dataset('speed-kinematics-categorical')
>>> datum = Y1.mean(axis=0) #arbitrary datum
>>> err = np.linspace(0.1, 2.5, datum.size)**2 #arbitrary error cloud
>>> pyplot.plot(datum, 'b', lw=3)
>>> spm1d.plot.plot_errorcloud(datum, err, facecolor='r', edgecolor='r')
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}