Generating very smooth random fields requires field padding to adhere to RFT expectations. This can be done easily using the pad keyword argument, but this becomes increasingly slow as FWHM increases.
To precisely reproduce partcular random fields, use np.random.seed:
>>> importnumpyasnp>>> importrft1d>>> np.random.seed(0)>>> a=rft1d.randn1d(5,101,20.0)>>> b=rft1d.randn1d(5,101,20.0)# a and b are different>>> np.random.seed(0)>>> c=rft1d.randn1d(5,101,20.0)# a and c are identical
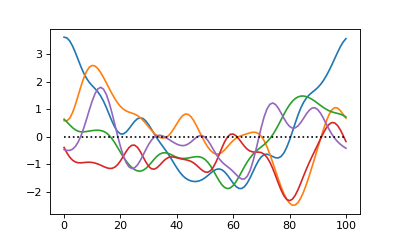
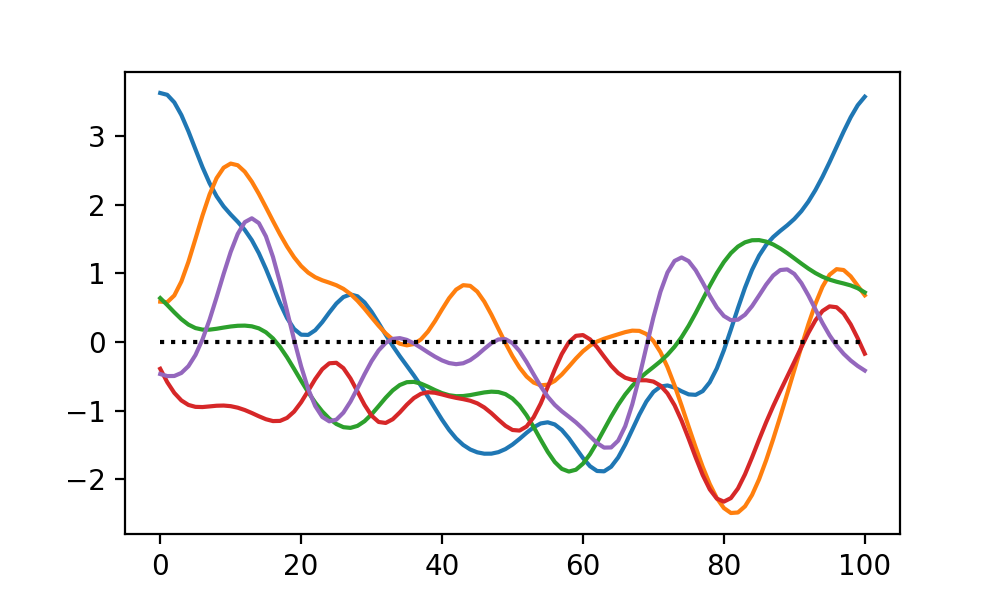
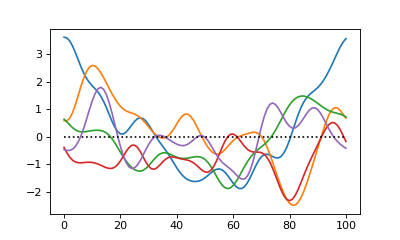
Fields may be sampled either in a node-based sense or in an element-based sense.
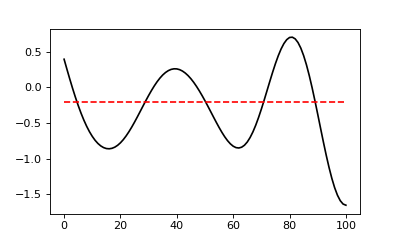
As suggested by the figure below, node-based sampling refers to discrete measurements
at single instants in time or at single points in space. Element-based sampling, on
the other hand, refers to measurements that span an interval.
Biomechanical time series (sampled at discrete instants)
Ocean wave heights (sampled by discrete sensors)
Element-based sampling:
Contact pressure distribution (average pressure acting over an area)
Long-interval time series (sampled daily, weekly or monthly, where each sample represents one whole day, week or month)
Node-based sampling is assumed by default in rft1d. Switching to element-based sampling can be done by setting the keyword “element_based” to True in relevant rft1d procedures.
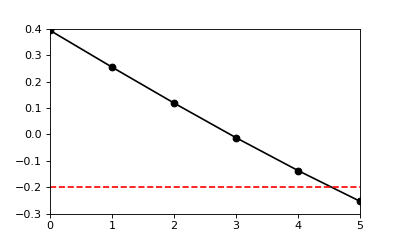
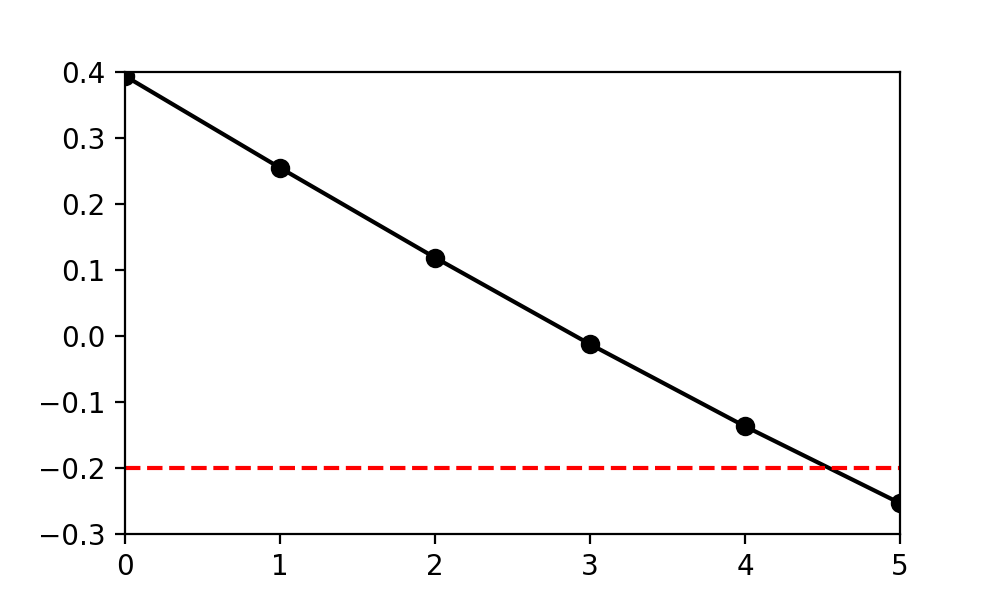
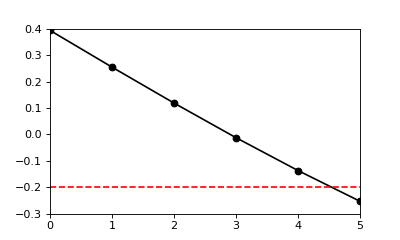
There are four supra-threshold nodes in the first upcrossing shown above, but the length of the upcrossing (i.e. its extent) is less than four. From the procedures above, cluster_extents and nSuprathresholdResels are reported as lengths.
By default cluster extents are interpolated to the threshold u. Disabling interpolation using the keyword interp is faster, and will yield integer extents:
Setting interp to False is faster, but it may cause disagreements between node-based and element-based sampling (if only one node exceeds u, the node-based extent is zero, but the element-based extent may be zero or one). If the upcrossing is large this difference is negligible, but for small upcrossing there may be strange results (i.e. upcrossing with an extent of zero). Recommendation: always interpolate.
RFT expectations regarding Gaussian random fields can be accessed via an interface
similar to scipy.stats. As an example, in scipy the survival function for
the standard normal distribution is given by:
Thus a 1D Gaussian random field with FWHM=10 and a field length of 100 is about 14 times more likely to reach
a height of 2.0 than is a 0D Gaussian scalar.
The most convenient way to explore RFT expectations and probabilities is with the rft1d.prob.RFTCalculator class:
Use rft1d.prob.RFTCalculator to generate theoretical predictions (see here)
Then use rft1d.randn1d to generate random fields (see here)
For each random field use rft1d.geom.ClusterMetricCalculator to compute upcrossing metrics (see here)
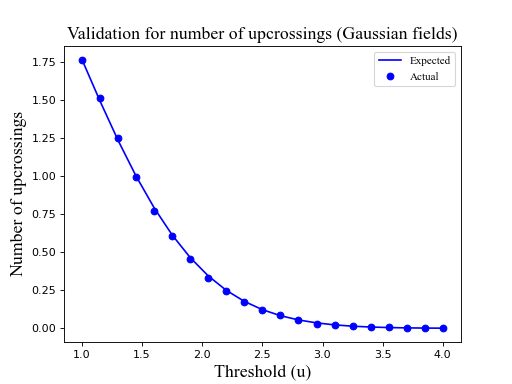
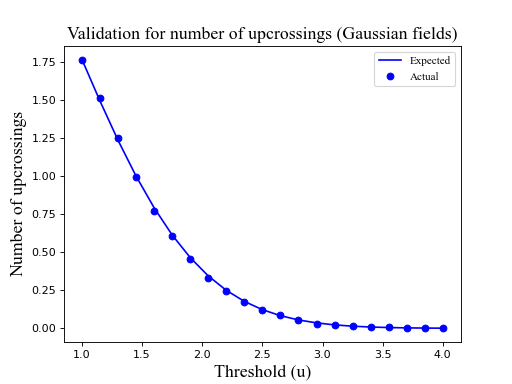
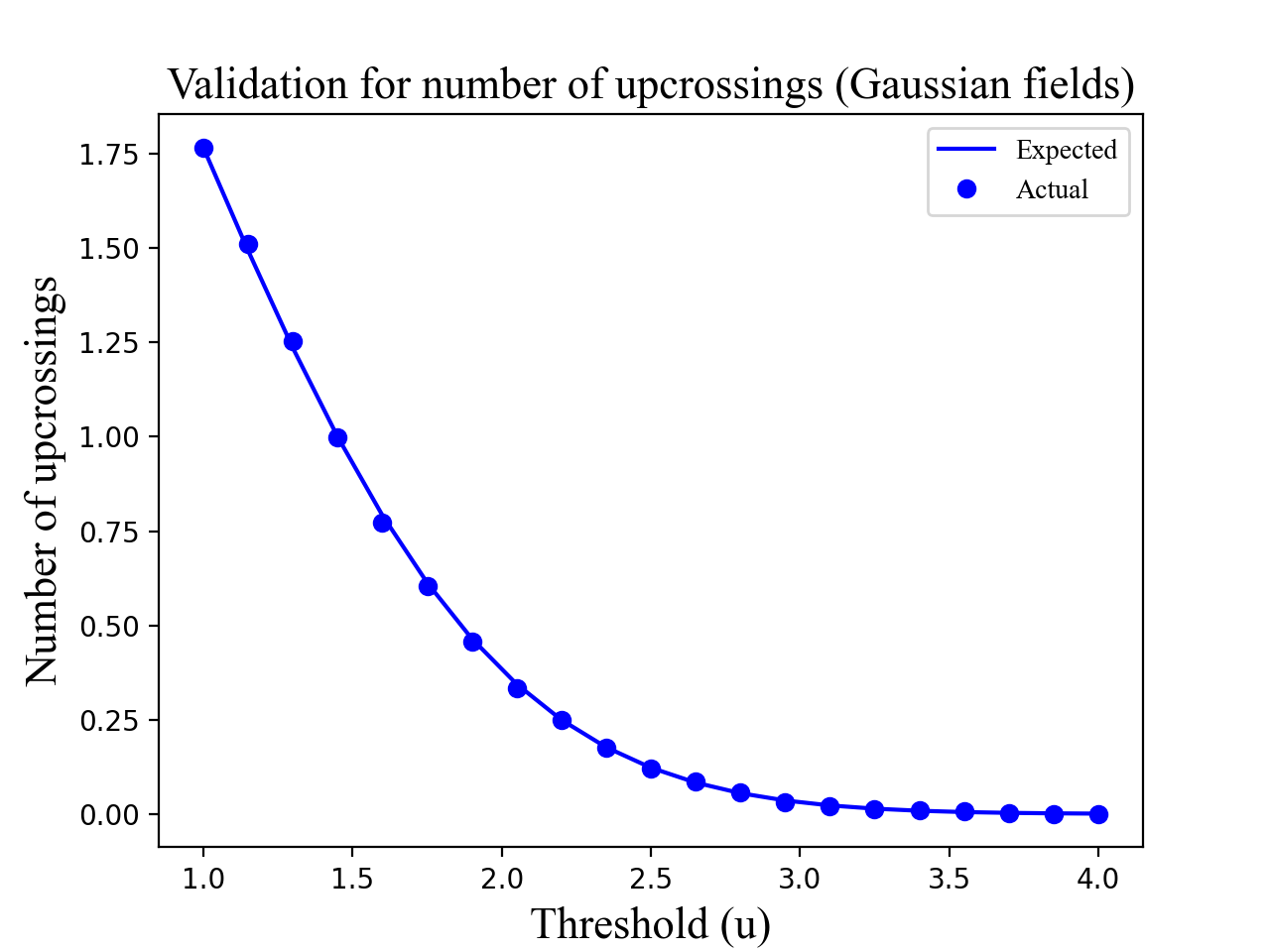
The figure below depicts a validation for the
expected number of upcrossings in Gaussian fields with FWHM=10. Click on the
“source code” link below to see details.
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}